|
Size: 34152
Comment:
|
Size: 618
Comment: Fixed apparent incorrect macro edit.
|
| Deletions are marked like this. | Additions are marked like this. |
| Line 1: | Line 1: |
| (see also TipsAndTricks) | #pragma section-numbers 2 = Mercurial Frequently Asked Questions = ''(see also TipsAndTricks)'' ||<<TableOfContents>> ||<style="vertical-align: top;"><<Include(FAQ/Subpages)>> || |
| Line 3: | Line 6: |
| = Mercurial Frequently Asked Questions = [[TableOfContents]] ---- |
|
| Line 7: | Line 10: |
| === What is the license of the project? === See [[License]] |
|
| Line 8: | Line 13: |
| === What is the license of the project? === | == Terminology == <<Include(FAQ/Terminology)>> |
| Line 10: | Line 16: |
| The project is available under the GNU General Public License, v2. See COPYING in the release for more details. | == General Usage == <<Include(FAQ/GeneralUsage)>> |
| Line 13: | Line 20: |
=== What can i configure in Mercurial === See in MercurialIni. === I get an error while cloning a remote repository via ssh === If your remote repository is cloned thusly {{{ hg clone ssh://USER@REMOTE/path/to/repo }}} And, you find that after successful ssh authentication you get the error message '''remote: abort: repository path/to/repo not found!''' , then you need to know the following: * Mercurial's remote repository syntax differs from syntax of other well known programs such as rsync, cvs - both of which use a `:` character to delimit {{{USER@REMOTE}}} from the path component ({{{/path/to/repo}}}). * The path to the remote repository is ''relative'' to {{{$HOME}}} of {{{USER}}}. i.e., it is {{{ ~USER/path/to/repo }}}. * Remember to use {{{hg -v clone ssh://USER@REMOTE/path/to/repo}}} and observe the remote command being executed via the ssh channel === I get an "ssl required" error message when trying to push changes === If you're on a network you trust you can add {{{ [web] push_ssl = false }}} in your <repository-name>/.hg/hgrc file. (Taken from HgWebDirStepByStep) There's a reason for requiring SSL, however. If you do not trust the network you are using do '''not''' change this. === I did an hg pull and my working directory is empty! === There are two parts to Mercurial: the repository and the working directory. {{{hg pull}}} pulls all new changes from a remote repository into the local one but doesn't alter the working directory. This keeps you from upsetting your work in progress, which may not be ready to merge with the new changes you've pulled and also allows you to manage merging more easily (see below about best practices). To update your working directory, run {{{hg update}}}. If you're sure you want to update your working directory on a pull, you can also use {{{hg pull -u}}}. This will refuse to merge or overwrite local changes. === I want to retrieve an old version of my project, what do I do? === You want {{{hg update -C <version>}}}, which will clobber your current version with the requested version. You '''don't''' want {{{hg revert <version>}}}, which reverts changes in your working directory back to that version, but '''keeps''' the current parents for the next checkin. This command exists for undoing changes in current versions, not for working on old versions. === hg status shows changed files but hg diff doesn't! === {{{hg status}}} reports when file '''contents''' or '''flags''' have changed relative to '''either''' parent. {{{hg diff}}} only reports changed '''contents''' relative to the first parent. You can see flag information with the {{{--git}}} option to {{{hg diff}}} and deltas relative to the other parent with {{{-r}}}. === hg export or log -p shows a strange diff for my merge! === The diff shown by {{{hg export}}} and {{{hg log}}} is always against the first parent for consistency. Also, the files listed are only the files that have changed relative to ''both'' parents. === I did an hg revert and my working directory still has changes in it! === You've probably done an {{{hg merge}}}, which means your working directory now has two parents according to {{{hg parents}}}. A subsequent {{{hg revert}}} will revert your working directory ''back to the primary parent'', thus leaving you with the differences between the two parents. {{{hg update -C}}} will revert the left files. If you're trying to switch between revisions in history, you probably want {{{hg update -C}}}. === I want a clean, empty working directory === The easiest thing to do is run {{{hg clone -U}}} which will create a fresh clone without checking out a working copy. '''Note''': you might want to copy hgrc file from your old repository. === I committed a change containing nuclear launch codes, how do I delete it permanently? === If you've just committed it, and you haven't done any other commits or pulls since, you may be able to use {{{rollback}}} to undo the last commit transaction: {{{ $ hg rollback rolling back last transaction }}} If you've made other changes but you haven't yet published it to the world, you can do something like the following: {{{ $ hg clone -r <untainted-revision> tainted-repo untainted-repo }}} The strip command in the mq extension may also be useful here for doing operations in place. This will get you a new repo without the tainted change or the ones that follow it. You can import the further changes with {{{hg export}}} and {{{hg import}}} or by using the TransplantExtension. See TrimmingHistory for possible future approaches. If you've already pushed your changes to a public repository that people have cloned from, the genie is out of the bottle. Good luck cleaning up your mess. ''“Judge Tries to Unring Bell Hanging Around Neck of Horse Already Out of Barn Being Carried on Ship That Has Sailed.” - William G. Childs'' === I tried to check in an empty directory and it failed! === Mercurial doesn't track directories, it only tracks files. Which works for just about everything, except directories with no files in them. As empty directories aren't terribly useful and it makes the system much simpler, we don't intend to fix this any time soon. A couple workarounds: * add a file, like "this-dir-intentionally-left-blank" * create the directory with your Makefiles or other build processes === I want to get an email when a commit happens! === See CommitHook for an example. === I'd like to put only some few files of a large directory tree (home dir for instance) under mercurial's control, and it is taking forever to diff or commit === Just do a {{{ printf "syntax: glob\n*\n" > .hgignore }}} or, if you are using 0.7 or below, {{{ printf ".*\n" > .hgignore }}} This will make hg ignore all files except those explicitly added. === Why is the modification time of files not restored on checkout? === If you use automatic build tools like make or distutils, some built files might not be updated if you checkout an older revision of a file. Additionally a newer changeset might have an older commit timestamp due to pulling from someone else or importing patches somebody has done some time ago, so checking out a ''newer'' changeset would have to make the files ''older'' in this case. If you need predictable timestamps you can use ''hg archive'', which can do something like a checkout in a separate directory. Because this directory is newly created, there is nothing like switching to a different changeset afterwards, therefore the above mentioned problems don't apply here. === My merge program failed, and now I don't know what to do === If your merge program fails you'll find yourself in a state where both hg up and hg merge produce the same, unhelpful output. {{{ abort: outstanding uncommitted merges }}} When this first happened, mercurial told you what to do, but if you've lost those instructions, how does one recover them? Why does hg merge not invoke merge again? Why the unhelpful output? === Any way to 'hg push' and have an automatic 'hg update' on the remote server? === {{{ [hooks] changegroup = hg update >&2 }}} This goes in .hg/hgrc on the remote repository. Output has to be redirected to stderr (or /dev/null), because stdout is used for the data stream. === How can store my HTTP login once and for all ? === You can specify the usename and password in the URL like: {{{ http://user:password@mydomain.org }}} Then add a new entry in the ''paths'' section of your hgrc file. == Terminology == === What are revision numbers, changeset IDs, and tags? === Mercurial will generally allow you to refer to a revision in three ways: by revision number, by changeset ID, and by tag. A revision number is a simple decimal number that corresponds with the ordering of commits in the local repository. It is important to understand that this ordering can change from machine to machine due to Mercurial's distributed, decentralized architecture. This is where changeset I``Ds come in. A changeset ID is a 160-bit identifier that uniquely describes a changeset and its position in the change history, regardless of which machine it's on. This is represented to the user as a 40 digit hexadecimal number. As that tends to be unwieldy, Mercurial will accept any unambiguous substring of that number when specifying versions. It will also generally print these numbers in "short form", which is the first 12 digits. You should always use some form of changeset ID rather than the local revision number when discussing revisions with other Mercurial users as they may have different revision numbering on their system. Finally, a tag is an arbitrary string that has been assigned a correspondence to a changeset ID. This lets you refer to revisions symbolically. === What are branches, heads, and the tip? === The central concept of Mercurial is branching. A 'branch' is simply an independent line of development. In most other version control systems, all users generally commit to the same line of development called 'the trunk' or 'the main branch'. In Mercurial, every developer effectively works on a private branch and there is no internal concept of 'the main branch'. Thus Mercurial works hard to make repeated merging between branches easy. Simply run {{{hg pull}}}, {{{hg merge}}} and commit the result. 'Heads' are simply the most recent commits on a branch. Technically, they are changesets which have no children. Merging is the process of joining points on two branches into one, usually at their current heads. Use "hg heads" to find the heads in the current repository. The 'tip' is the most recently changed head, and also the highest numbered revision. If you have just made a commit, that commit will be the tip. Alternately, if you have just pulled from another repository, the tip of that repository becomes the current tip. The 'tip' is the default revision for many commands such as update, and also functions as a special symbolic tag. == General Usage == === How does merging work? === The merge process is simple. Usually you will want to merge the tip into your working directory. Thus you run {{{hg merge}}} and Mercurial will incorporate the changes from tip into your local changes. The first step of this process is tracing back through the history of changesets and finding the 'common ancestor' of the two versions that are being merged. This is done on a project-wide and a file by file basis. For files that have been changed in both projects, a three-way merge is attempted to add the changes made remotely into the changes made locally. If there are conflicts between these changes, the user is prompted to interactively resolve them. Mercurial uses a helper tool for this, which is usually found by the hgmerge script. Example tools include tkdiff, kdiff3, and the classic RCS merge. After you've completed the merge and you're satisfied that the results are correct, it's a good idea to commit your changes. Mercurial won't allow you to perform another merge until you've done this commit as that would lose important history that will be needed for future merges. === What are some best practices for distributed development with Mercurial? === First, merge often! This makes merging easier for everyone and you find out about conflicts (which are often rooted in incompatible design decisions) earlier. Second, don't hesitate to use multiple trees locally. Mercurial makes this fast and light-weight. Typical usage is to have an incoming tree, an outgoing tree, and a separate tree for each area being worked on. The incoming tree is best maintained as a pristine copy of the upstream repository. This works as a cache so that you don't have to pull multiple copies over the network. No need to check files out here as you won't be changing them. The outgoing tree contains all the changes you intend for merge into upsteam. Publish this tree with {{{hg serve}}} or hgweb.cgi or use {{{hg push}}} to push it to another publicly availabe repository. Then, for each feature you work on, create a new tree. Commit early and commit often, merge with incoming regularly, and once you're satisfied with your feature, pull the changes into your outgoing tree. === How do I import from a repository created in a different SCM? === See ConvertingRepositories for various tips. === What about Windows support? === See WindowsInstall for getting started using Windows. === Is there a GUI front-end? === See ["GUIClients"] for information on graphical merge tools and other front-ends. == Tags == === How do tags work in Mercurial? === Tags work slightly differently in Mercurial than most revision systems. The design attempts to meet the following requirements: * be version controlled and mergeable just like any other file * allow signing of tags * allow adding a tag to an already committed changeset * allow changing tags in the future Thus Mercurial stores tags as a file in the working dir. This file is called .hgtags and consists of a list of changeset I``Ds and their corresponding tags. To add a tag to the system, simply add a line to this file and then commit it for it to take effect. The {{{hg tag}}} command will do this for you and {{{hg tags}}} will show the currently effective tags. Note that because tags refer to changeset I``Ds and the changeset ID is effectively the sum of all the contents of the repository for that change, it is impossible in Mercurial to simultaneously commit and add a tag. Thus tagging a revision must be done as a second step. === What if I want to just keep local tags? === You can use "hg tag" command with an option {{{-l}}} or {{{--local}}}. This will store the tag in the file .hg/localtags, which will not be distributed or versioned. The format of this file is identical to the one of .hgtags and the tags stored there are handled the same. === How do tags work with multiple heads? === The tags that are in effect at any given time are the tags specified in each head, with heads closer to the tip taking precedence. Local tags override all other tags. === What if multiple lines with different revisions use the same tag name in .hgtags? === Only the last line where the tag appears is taken into account. The behavior is identical when this happens in .hg/localtags. |
<<Include(FAQ/CommonProblems)>> |
| Line 343: | Line 23: |
=== I found a bug, what do I do? === Report it to the mercurial mailing list, mercurial@selenic.com or in the bug tracker http://www.selenic.com/mercurial/bts/ === What should I include in my bug report? === Enough information to reproduce or diagnose the bug. If you can, try using the hg -v and hg -d switches to figure out exactly what Mercurial is doing. If you can reproduce the bug in a simple repository, that is very helpful. The best is to create a simple shell script to automate this process, which can then be added to our test suite. === Can Mercurial do <x>? === If you'd like to request a feature, send your request to mercurial@selenic.com. As Mercurial is still very new, there are certainly features it is missing and you can give us feedback on how best to implement them. Be sure to see ToDo and MissingFeatures to see what's already planned and where we need help. |
<<Include(FAQ/BugsAndFeatures)>> |
| Line 371: | Line 26: |
=== How do I link to the latest revision of a file? === Find the URL for the file and then replace the changeset identifier with {{{tip}}}. |
<<Include(FAQ/WebInterface)>> |
| Line 377: | Line 29: |
=== What limits does Mercurial have? === Mercurial currently assumes that single files, indices, and manifests can fit in memory for efficiency. There should otherwise be no limits on file name length, file size, file contents, number of files, or number of revisions. The network protocol is big-endian. File names cannot contain the null character or newlines. Committer addresses cannot contain newlines. Mercurial is primarily developed for UNIX systems, so some U``NIXisms may be present in ports. === How does Mercurial store its data? === The fundamental storage type in Mercurial is a "revlog". A revlog is the set of all revisions of a named object. Each revision is either stored compressed in its entirety or as a compressed binary delta against the previous version. The decision of when to store a full version is made based on how much data would be needed to reconstruct the file. This lets us ensure that we never need to read huge amounts of data to reconstruct a object, regardless of how many revisions of it we store. In fact, we should always be able to do it with a single read, provided we know when and where to read. This is where the index comes in. Each revlog has an index containing a special hash (nodeid) of the text, hashes for its parents, and where and how much of the revlog data we need to read to reconstruct it. Thus, with one read of the index and one read of the data, we can reconstruct any version in time proportional to the object size. Similarly, revlogs and their indices are append-only. This means that adding a new version is also O(1) seeks. Revlogs are used to represent all revisions of files, manifests, and changesets. Compression for typical objects with lots of revisions can range from 100 to 1 for things like project makefiles to over 2000 to 1 for objects like the manifest. === How does Mercurial handle binary files? === See BinaryFiles. === What about Windows line endings vs. Unix line endings? === See EncodeDecodeFilter. === What about keyword replacement (i.e. $Id$)? === See KeywordPlan and KeywordExpansionExtension. === How are Mercurial diffs and deltas calculated? === Mercurial diffs are calculated rather differently than those generated by the traditional diff algorithm (but with output that's completely compatible with patch of course). The algorithm is an optimized C implementation based on Python's [http://python.org/doc/2.4.1/lib/module-difflib.html difflib], which is intended to generate diffs that are easier for humans to read rather than be 'minimal'. This same algorithm is also used for the internal delta compression. In the course of investigating delta compression algorithms, we discovered that this implementation was simpler and faster than the competition in our benchmarks and also generated smaller deltas than the theoretically 'minimal' diffs of the traditional diff algorithms. This is because the traditional algorithm assumes the same cost for insertions, deletions, and unchanged elements. === How are manifests and changesets stored? === A manifest is simply a list of all files in a given revision of a project along with the nodeids of the corresponding file revisions. So grabbing a given version of the project means simply looking up its manifest and reconstructing all the file revisions pointed to by it. A changeset is a list of all files changed in a check-in along with a change description and some metadata like user and date. It also contains a nodeid to the relevant revision of the manifest. === How do Mercurial hashes get calculated? === Mercurial hashes both the contents of an object and the hash of its parents to create an identifier that uniquely identifies an object's contents and history. This greatly simplifies merging of histories because it avoid graph cycles that can occur when a object is reverted to an earlier state. All file revisions have an associated hash value. These are listed in the manifest of a given project revision, and the manifest hash is listed in the changeset. The changeset hash is again a hash of the changeset contents and its parents, so it uniquely identifies the entire history of the project to that point. === What checks are there on repository integrity? === Every time a revlog object is retrieved, it is checked against its hash for integrity. It is also incidentally doublechecked by the Adler32 checksum used by the underlying zlib compression. Running 'hg verify' decompresses and reconstitutes each revision of each object in the repository and cross-checks all of the index metadata with those contents. But this alone is not enough to ensure that someone hasn't tampered with a repository. For that, you need cryptographic signing. === How does signing work with Mercurial? === Take a look at the hgeditor script for an example. The basic idea is to use GPG to sign the manifest ID inside that changelog entry. The manifest ID is a recursive hash of all of the files in the system and their complete history, and thus signing the manifest hash signs the entire project contents. === What about hash collisions? What about weaknesses in SHA1? === The SHA1 hashes are large enough that the odds of accidental hash collision are negligible for projects that could be handled by the human race. The known weaknesses in SHA1 are currently still not practical to attack, and Mercurial will switch to SHA256 hashing before that becomes a realistic concern. Collisions with the "short hashes" are not a concern as they're always checked for ambiguity and are still long enough that they're not likely to happen for reasonably-sized projects (< 1M changes). == Mercurial Book == Mercuial book is built bye simple command of "make". The book building process is automated into a Makefile callup different software tools. The main tool is the powerful TeX software plus followings. 1. Graphivz: To generated graph without GUI operations. 1. Inkscape: SVG to EPS graph format conversion. 1. Tex4ht: a system for authoring hypertext with TeX and friends === How do I configure the book build framework using VMWare appliance approach ? === 1. [http://www.vmware.com/download/player/ Download VMWare player 2.0] or using VMWare workstation/VMWare ESX if you have a license. 1. [http://download.thoughtpolice.co.uk/fedora-7-i386.zip.torrent Download Fedora 7 vmware image] from [http://www.thoughtpolice.co.uk/vmware/ Though police]. 1. Use YUM install the missing rpm packages. {{{ [root@localhost ~]# yum install yum graphviz tetex mercurial rcs inkscape patchutils tex4ht }}} 1. Pull hg book source from [http://hg.serpentine.com/mercurial/book hg.serpentine.com book source repository]. {{{ [root@localhost ~]# hg clone http://hg.serpentine.com/mercurial/book destination directory: book requesting all changes adding changesets adding manifests adding file changes added 277 changesets with 855 changes to 319 files 315 files updated, 0 files merged, 0 files removed, 0 files unresolved [root@localhost ~]# }}} 1. Do a drive run to see what is going to happen. {{{ [root@localhost en]# make -n echo -n '92660e72d6bf, dated 2007-12-07 21:25 -0800,' > build_id.tex echo -n 'Mercurial Distributed SCM (version 0.9.4)' > hg_id.tex dot -Tps -o feature-branches.eps feature-branches.dot epstopdf feature-branches.eps dot -Tps -o undo-manual.eps undo-manual.dot epstopdf undo-manual.eps dot -Tps -o undo-manual-merge.eps undo-manual-merge.dot epstopdf undo-manual-merge.eps dot -Tps -o undo-non-tip.eps undo-non-tip.dot epstopdf undo-non-tip.eps dot -Tps -o undo-simple.eps undo-simple.dot epstopdf undo-simple.eps inkscape -E filelog.eps filelog.svg epstopdf filelog.eps inkscape -E metadata.eps metadata.svg epstopdf metadata.eps inkscape -E mq-stack.eps mq-stack.svg epstopdf mq-stack.eps inkscape -E revlog.eps revlog.svg epstopdf revlog.eps inkscape -E snapshot.eps snapshot.svg epstopdf snapshot.eps inkscape -E tour-history.eps tour-history.svg epstopdf tour-history.eps inkscape -E tour-merge-conflict.eps tour-merge-conflict.svg epstopdf tour-merge-conflict.eps inkscape -E tour-merge-merge.eps tour-merge-merge.svg epstopdf tour-merge-merge.eps inkscape -E tour-merge-pull.eps tour-merge-pull.svg epstopdf tour-merge-pull.eps inkscape -E tour-merge-sep-repos.eps tour-merge-sep-repos.svg epstopdf tour-merge-sep-repos.eps inkscape -E wdir.eps wdir.svg epstopdf wdir.eps inkscape -E wdir-after-commit.eps wdir-after-commit.svg epstopdf wdir-after-commit.eps inkscape -E wdir-branch.eps wdir-branch.svg epstopdf wdir-branch.eps inkscape -E wdir-merge.eps wdir-merge.svg epstopdf wdir-merge.eps inkscape -E wdir-pre-branch.eps wdir-pre-branch.svg epstopdf wdir-pre-branch.eps cd examples && ./run-example backout cd examples && ./run-example bisect cd examples && ./run-example branching cd examples && ./run-example branch-named cd examples && ./run-example branch-repo cd examples && ./run-example cmdref cd examples && ./run-example daily.copy cd examples && ./run-example daily.files cd examples && ./run-example daily.rename cd examples && ./run-example daily.revert cd examples && ./run-example extdiff cd examples && ./run-example filenames cd examples && ./run-example hook.msglen cd examples && ./run-example hook.simple cd examples && ./run-example hook.ws cd examples && ./run-example issue29 cd examples && ./run-example mq.guards cd examples && ./run-example mq.qinit-help cd examples && ./run-example mq.dodiff cd examples && ./run-example mq.id cd examples && ./run-example mq.tarball cd examples && ./run-example mq.tools cd examples && ./run-example mq.tutorial cd examples && ./run-example rename.divergent cd examples && ./run-example rollback cd examples && ./run-example tag cd examples && ./run-example template.simple cd examples && ./run-example template.svnstyle cd examples && ./run-example tour cd examples && ./run-example tour-merge-conflict touch examples/.run mkdir -p pdf/ TEXINPUTS=./: pdflatex -interaction batchmode -output-directory pdf/ -jobname hgbook 00book.tex || (rm -f pdf/hgbook.pdf; exit 1) cp 99book.bib pdf/ cd pdf/ && bibtex hgbook cd pdf/ && makeindex hgbook TEXINPUTS=./: pdflatex -interaction batchmode -output-directory pdf/ -jobname hgbook 00book.tex || (rm -f pdf/hgbook.pdf; exit 1) TEXINPUTS=./: pdflatex -interaction batchmode -output-directory pdf/ -jobname hgbook 00book.tex || (rm -f pdf/hgbook.pdf; exit 1) if grep 'Reference.*undefined' pdf/hgbook.log; then exit 1; fi dot -Tsvg -o feature-branches.svg feature-branches.dot inkscape -D -e feature-branches.png feature-branches.svg dot -Tsvg -o undo-manual.svg undo-manual.dot inkscape -D -e undo-manual.png undo-manual.svg dot -Tsvg -o undo-manual-merge.svg undo-manual-merge.dot inkscape -D -e undo-manual-merge.png undo-manual-merge.svg dot -Tsvg -o undo-non-tip.svg undo-non-tip.dot inkscape -D -e undo-non-tip.png undo-non-tip.svg dot -Tsvg -o undo-simple.svg undo-simple.dot inkscape -D -e undo-simple.png undo-simple.svg inkscape -D -e filelog.png filelog.svg inkscape -D -e metadata.png metadata.svg inkscape -D -e mq-stack.png mq-stack.svg inkscape -D -e revlog.png revlog.svg inkscape -D -e snapshot.png snapshot.svg inkscape -D -e tour-history.png tour-history.svg inkscape -D -e tour-merge-conflict.png tour-merge-conflict.svg inkscape -D -e tour-merge-merge.png tour-merge-merge.svg inkscape -D -e tour-merge-pull.png tour-merge-pull.svg inkscape -D -e tour-merge-sep-repos.png tour-merge-sep-repos.svg inkscape -D -e wdir.png wdir.svg inkscape -D -e wdir-after-commit.png wdir-after-commit.svg inkscape -D -e wdir-branch.png wdir-branch.svg inkscape -D -e wdir-merge.png wdir-merge.svg inkscape -D -e wdir-pre-branch.png wdir-pre-branch.svg mkdir -p html/onepage/ cp 99book.bib html/onepage/ TEXINPUTS=./: ./htlatex.book 00book.tex "bookhtml,html4-uni," " -cunihtf -utf8" "html/onepage/" "-interaction batchmode -output-directory html/onepage/ -jobname hgbook" || (rm -f html/onepage/hgbook.html; exit 1) cd html/onepage/ && tex4ht -f/hgbook -cvalidate -cunihtf cd html/onepage/ && t4ht -f/hgbook ./fixhtml.py html/onepage//*.html rm html/onepage//hgbook.css cp hgbook.css html/onepage/hgbook.css cp feature-branches.png html/onepage/feature-branches.png cp undo-manual.png html/onepage/undo-manual.png cp undo-manual-merge.png html/onepage/undo-manual-merge.png cp undo-non-tip.png html/onepage/undo-non-tip.png cp undo-simple.png html/onepage/undo-simple.png cp filelog.png html/onepage/filelog.png cp metadata.png html/onepage/metadata.png cp mq-stack.png html/onepage/mq-stack.png cp revlog.png html/onepage/revlog.png cp snapshot.png html/onepage/snapshot.png cp tour-history.png html/onepage/tour-history.png cp tour-merge-conflict.png html/onepage/tour-merge-conflict.png cp tour-merge-merge.png html/onepage/tour-merge-merge.png cp tour-merge-pull.png html/onepage/tour-merge-pull.png cp tour-merge-sep-repos.png html/onepage/tour-merge-sep-repos.png cp wdir.png html/onepage/wdir.png cp wdir-after-commit.png html/onepage/wdir-after-commit.png cp wdir-branch.png html/onepage/wdir-branch.png cp wdir-merge.png html/onepage/wdir-merge.png cp wdir-pre-branch.png html/onepage/wdir-pre-branch.png cp kdiff3.png html/onepage/kdiff3.png cp note.png html/onepage/note.png mkdir -p html/split/ cp 99book.bib html/split/ TEXINPUTS=./: ./htlatex.book 00book.tex "bookhtml,html4-uni,2" " -cunihtf -utf8" "html/split/" "-interaction batchmode -output-directory html/split/ -jobname hgbook" || (rm -f html/split/hgbook.html; exit 1) cd html/split/ && tex4ht -f/hgbook -cvalidate -cunihtf cd html/split/ && t4ht -f/hgbook ./fixhtml.py html/split//*.html rm html/split//hgbook.css cp hgbook.css html/split/hgbook.css cp feature-branches.png html/split/feature-branches.png cp undo-manual.png html/split/undo-manual.png cp undo-manual-merge.png html/split/undo-manual-merge.png cp undo-non-tip.png html/split/undo-non-tip.png cp undo-simple.png html/split/undo-simple.png cp filelog.png html/split/filelog.png cp metadata.png html/split/metadata.png cp mq-stack.png html/split/mq-stack.png cp revlog.png html/split/revlog.png cp snapshot.png html/split/snapshot.png cp tour-history.png html/split/tour-history.png cp tour-merge-conflict.png html/split/tour-merge-conflict.png cp tour-merge-merge.png html/split/tour-merge-merge.png cp tour-merge-pull.png html/split/tour-merge-pull.png cp tour-merge-sep-repos.png html/split/tour-merge-sep-repos.png cp wdir.png html/split/wdir.png cp wdir-after-commit.png html/split/wdir-after-commit.png cp wdir-branch.png html/split/wdir-branch.png cp wdir-merge.png html/split/wdir-merge.png cp wdir-pre-branch.png html/split/wdir-pre-branch.png cp kdiff3.png html/split/kdiff3.png cp note.png html/split/note.png rm undo-non-tip.eps wdir-after-commit.eps wdir-merge.eps undo-manual.eps wdir-branch.eps metadata.eps snapshot.eps wdir-pre-branch.eps tour-merge-sep-repos.eps tour-merge-pull.eps revlog.eps tour-merge-conflict.eps tour-merge-merge.eps feature-branches.svg undo-manual-merge.eps undo-simple.svg feature-branches.eps undo-simple.eps tour-history.eps filelog.eps wdir.eps mq-stack.eps undo-manual-merge.svg undo-non-tip.svg undo-manual.svg [root@localhost en]# }}} === How do I back out the changes in Mercurial book ? === 1. Backout to a known working copy to discard the changes. 1. Ex. the changes set after "271:8627f718517a" break the book building on Fedora 7(also on 6 and 8). 1. Error message, failed at "run-example bisect". {{{ cd examples && ./run-example backout running backout .............. cd examples && ./run-example bisect running bisect ..... Output of bisect.search.init has changed! --- bisect.search.init.out 2007-12-08 07:47:25.000000000 -0500 +++ bisect.search.init.err 2007-12-08 07:52:01.000000000 -0500 @@ -1,3 +1 @@ - - ....... (exit 0) make: *** [examples/bisect.run] Error 1 rm undo-non-tip.eps wdir-after-commit.eps wdir-merge.eps undo-manual.eps wdir-br anch.eps metadata.eps snapshot.eps wdir-pre-branch.eps tour-merge-sep-repos.eps tour-merge-pull.eps revlog.eps tour-merge-conflict.eps tour-merge-merge.eps undo -manual-merge.eps feature-branches.eps undo-simple.eps tour-history.eps filelog. eps wdir.eps mq-stack.eps [root@localhost en]# }}} 1. The change logs {{{ [root@localhost book]# hg log | head -40 changeset: 276:92660e72d6bf tag: tip user: "Dongsheng Song" <dongsheng.song@gmail.com> date: Fri Dec 07 21:25:07 2007 -0800 summary: [hgbook] Fix a typo changeset: 275:96ea24a916f9 parent: 274:b049cb10bde3 parent: 273:00f69e8825c5 user: Bryan O'Sullivan <bos@serpentine.com> date: Mon Nov 26 20:42:36 2007 -0800 summary: Merge with myself. changeset: 274:b049cb10bde3 parent: 271:8627f718517a user: Bryan O'Sullivan <bos@serpentine.com> date: Mon Nov 26 20:42:17 2007 -0800 summary: Add a link to myself. changeset: 273:00f69e8825c5 user: Bryan O'Sullivan <bos@serpentine.com> date: Mon Nov 26 12:24:53 2007 -0800 summary: Bring book up to date with recent changes. changeset: 272:74c079e0051f user: Bryan O'Sullivan <bos@serpentine.com> date: Mon Nov 26 11:18:46 2007 -0800 summary: Account for change in bisect output. changeset: 271:8627f718517a user: Max Vozeler <max@nusquama.org> date: Mon Sep 10 19:38:41 2007 +0200 summary: Fix typo "paptches" changeset: 270:4c767178c1aa user: Eric Hanchrow <offby1@blarg.net> date: Mon Jun 04 13:23:53 2007 -0700 summary: Fix typos changeset: 269:abfe426f7e08 [root@localhost book]# }}} 1. run the following commands to undo the change after Sept 10 2007. {{{ }}} |
<<Include(FAQ/TechnicalDetails)>> |
Mercurial Frequently Asked Questions
(see also TipsAndTricks)
1. General Questions
1.1. What is the license of the project?
See License
2. Terminology
2.1. What are revision numbers, changeset IDs, and tags?
Mercurial will generally allow you to refer to a revision in three ways: by revision number, by changeset ID, and by tag.
A revision number is a simple decimal number that corresponds with the ordering of commits in the local repository. It is important to understand that this ordering can change from machine to machine due to Mercurial's distributed, decentralized architecture.
This is where changeset IDs come in. A changeset ID is a 160-bit identifier that uniquely describes a changeset and its position in the change history, regardless of which machine it's on. This is represented to the user as a 40 digit hexadecimal number. As that tends to be unwieldy, Mercurial will accept any unambiguous substring of that number when specifying versions. It will also generally print these numbers in "short form", which is the first 12 digits.
You should always use some form of changeset ID rather than the local revision number when discussing revisions with other Mercurial users as they may have different revision numbering on their system.
Finally, a tag is an arbitrary string that has been assigned a correspondence to a changeset ID. This lets you refer to revisions symbolically.
2.2. What are cloning, pulling, and pushing?
In many other version control systems, all developers commit changes to a single, centralized repository. In Mercurial, every developer typically works in his or her own repository. A fundamental concept of Mercurial is transferring changesets among repositories. This is accomplished through the clone, push, and pull operations (see also CommunicatingChanges).
To begin a task on an existing project, a developer will typically create a local copy of the repository using the hg clone command. This operation creates a new repository containing all the files and all of their history.
If another developer has made changes to her repository, you can pull her changes into your repository using the hg pull command. If you have made changes to your repository and you wish to transfer them to another repository (say, to a shared repository), you would do this using the hg push command.
2.3. What are branches, merges, heads, and the tip?
In the simplest case, history consists of a linear sequence of changesets. In this case, every changeset (except for the first and last) has one parent and one child. For a variety of reasons, it is possible for the history graph to split into two or more independent lines of development. When this occurs, the history graph is said to have a branch. Where a branch occurs, a changeset has two or more children.
When two lines of development are joined into a single line, a merge is said to have occurred. Where a merge occurs, a changeset has two parents. If a line of development is not merged into another, the last changeset on that line is referred to as the head of that branch. Every repository always includes one or more heads. Heads have no children. Use the hg heads command to list the heads of the current repository.
The tip is the changeset added to the repository most recently. If you have just made a commit, that commit will be the tip. Alternately, if you have just pulled from another repository, the tip of that repository becomes the new tip. Use hg tip to show the tip of the repository.
The tip is always a head. If there are multiple heads in a repository, only one of them is the tip. Within a repository, changesets are numbered sequentially, so the tip has the highest sequence number. The word "tip" functions as a special tag to denote the tip changeset, and it can be used anywhere a changeset ID or tag is valid.
The following diagram illustrates these concepts.
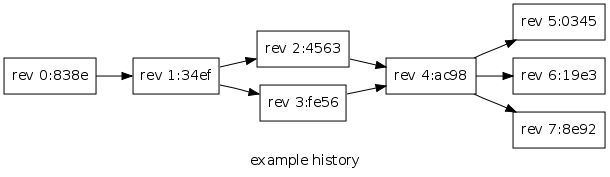
The history has branched at revs 1:34ef and 4:ac98, and a merge has occurred at rev 4:ac98. Revs 5:0345, 6:19e3, and 7:8e92 are heads, and 7:8e92 is the tip.
Note that while hg tip shows the tip and hg heads shows the heads of the repository, the hg branch and hg branches commands do not list the branch changesets as described above. Instead, they show changesets corresponding to branches that have been given names. See NamedBranches.
The term "branch" has other meanings as well. See Branch for a fuller discussion.
3. General Usage
3.1. How does merging work?
See documentation for the merge command.
3.2. What are some best practices for distributed development with Mercurial?
See some typical working practices.
3.3. How do I import from a repository created in a different SCM?
See the Converting Repositories document for various tips.
3.4. What about Windows support?
See the Windows install guide for getting started using Windows.
Like TortoiseSVN, we recommend to turn off the indexing service on the working copies and repositories, and exclude them from virus scans.
3.5. Is there a GUI front-end?
See the page of related tools for information on graphical merge tools and other front-ends.
3.6. How do I make sure that only known people can contribute/submit/commit/push changes?
Since Mercurial lets users do anything they want with their repository clones, sharing them with whoever they like, enforcing restrictions on commits is not generally possible with Mercurial (note, however, that committing in centralised version control systems' and Mercurial's commit operation are not exactly the same thing). However, the critical operation is actually the push operation, since it is at such a point that changes are communicated between repository clones, and where an "official" repository would want to be able to reject "unverified" changesets: that is, changesets from people who are unknown or not authorised to contribute changes. So, although many clones may potentially exist with any individual (known or unknown) doing what they like, any work that makes its way to the "official" repository must have someone who is "verified" or "authorised" pushing that work; that person effectively takes responsibility for the work's suitability.
One extension which attempts to provide a verification capability is the commitsigs extension.
(Although one can argue that in centralised version control systems, where each person has a login to a central repository, the task of verifying submitters is easier, there is also no guarantee that work submitted by another person has not somehow incorporated changes made by an "unauthorised" person. After all, it is possible to share the contents of repositories by other means - perhaps a user lets other people on a system access their checkout directly in the filesystem - and thus the act of submitting work by an "authorised" person is no guarantee that they did the work all by themself, merely that they take responsibility for it.)
4. Common Problems
4.1. Windows: The installer aborts with an error message
"This installation package is not supported by this processor type. Contact your product vendor." This means you are trying to install a 64-bit version installer on a normal 32-bit operating system. You need to download and use the correct msi file for your OS. For normal 32-bit OS, make sure the msi file does not have an x64 in it.
4.2. Which revision have I checked out?
Use the summary command (TutorialClone shows an example call). The summary command will also tell you in brief what branch you're on, whether there are any newer changes than the one you're on, and what the state of your working directory is.
If you want this for a script and need terser output, take a look at identify command flags and at scripting.
4.3. What can I configure in Mercurial
See in MercurialIni.
4.4. Configuring the username
If hg says No username found, using 'user@hostname instead' when you make a commit, then you need to configure your username. Please see QuickStart for help on this.
4.5. My repository is corrupted, help!
Please read the page "Dealing With Repository And Dirstate Corruption" for recommendations on what to do.
4.6. I get an error while cloning a remote repository via ssh
If your remote repository is cloned thusly
hg clone ssh://USER@REMOTE/path/to/repo
And, you find that after successful ssh authentication you get the error message remote: abort: repository path/to/repo not found! , then you need to know the following:
Mercurial's remote repository syntax differs from syntax of other well known programs such as rsync, cvs - both of which use a : character to delimit USER@REMOTE from the path component (/path/to/repo).
The path to the remote repository is relative to $HOME of USER. i.e., it is ~USER/path/to/repo .
Remember to use hg -v clone ssh://USER@REMOTE/path/to/repo and observe the remote command being executed via the ssh channel
On the other hand, if the error message is remote: bash: line 1: hg: command not found, the problem is that the environment used by ssh does not have hg in its PATH. There are a few ways to deal with this problem:
In your client ~/.hgrc file, set a remotecmd value in the [ui] section giving the exact path to hg.
- As a one-off operation, you could write the clone command as follows:
hg --config ui.remotecmd=/path/to/hg clone ssh://USER@REMOTE/path/to/repo
Define a PATH in .bashrc (or equivalent shell configuration file), noting that this may not always work for some versions of ssh and bash.
On the server, create a ~/.ssh/environment file that defines an appropriate PATH, and add PermitUserEnvironment yes to /etc/sshd_config.
On the server, place a symlink to the hg binary somewhere on the ssh PATH; run ssh username@server env to show it. Be careful to avoid paths managed by system package management, since package installations could conflict with it; /usr/local/bin is usually a good choice.
4.7. I get an "ssl required" error message when trying to push changes
That's because allowing anonymous, unauthenticated HTTP clients to push changes into your repository would be a huge security hole. If you are on a private network and you know that all HTTP clients are trustworthy, you can add
[web] push_ssl = false
to .hg/hgrc on the server-side repository. (See also HgWebDirStepByStep.)
There's a reason for requiring SSL, however. If you do not trust the network you are using do not change this.
4.8. I did an hg pull and my working directory is empty!
There are two parts to Mercurial: the repository and the working directory. hg pull pulls all new changes from a remote repository into the local one but doesn't alter the working directory.
This keeps you from upsetting your work in progress, which may not be ready to merge with the new changes you've pulled and also allows you to manage merging more easily (see below about best practices).
To update your working directory, run hg update. If you're sure you want to update your working directory on a pull, you can also use hg pull -u. This will refuse to merge or overwrite local changes.
4.9. I want to retrieve an old version of my project, what do I do?
You want hg update -C <version>, which will clobber your current version with the requested version.
You don't want hg revert <version>, which reverts changes in your working directory back to that version, but keeps the current parents for the next checkin. This command exists for undoing changes in current versions, not for working on old versions.
4.10. hg status shows changed files but hg diff doesn't!
hg status reports when file contents or flags have changed relative to either parent. hg diff only reports changed contents relative to the first parent. You can see flag information with the --git option to hg diff and deltas relative to the other parent with -r.
4.11. hg export or log -p shows a strange diff for my merge!
The diff shown by hg diff, hg export and hg log is always against the first parent for consistency. Also, the files listed are only the files that have changed relative to both parents.
(Are diffs of merges really always against the first parent? Doesn't hg export have a --switch-parent option? It would also be good if the docs would give the rationale for hg diff and hg log not having that option (assuming they don't--the man page only mentions it for export).)
4.12. I did an hg revert and my working directory still has changes in it!
You've probably done an hg merge (see Merge), which means your working directory now has two parents according to hg parents. A subsequent hg revert --all -r . will revert all files in the working directory back to the first (primary) parent, but it will still leave you with two parents (see revert).
To completely undo the uncommitted merge and discard all local modifications, you will need to issue a hg update -C -r . (note the "dot" at the end of the command).
See also TutorialMerge.
4.13. I want a clean, empty working directory
The easiest thing to do is run hg clone -U which will create a fresh clone without checking out a working copy.
If the repository already has a working copy, you can remove it running hg update null.
Note: you might want to copy hgrc file from your old repository.
4.14. I committed a change containing nuclear launch codes, how do I delete it permanently?
If you've just committed it, and you haven't done any other commits or pulls since, you may be able to use rollback command to undo the last commit transaction:
$ hg rollback rolling back last transaction
If you've made other changes but you haven't yet published it to the world, you can do something like the following:
$ hg clone -r <untainted-revision> tainted-repo untainted-repo
The strip command in the mq extension may also be useful here for doing operations in place.
This will get you a new repo without the tainted change or the ones that follow it. You can import the further changes with hg export and hg import or by using the TransplantExtension. See TrimmingHistory for possible future approaches.
If you've already pushed your changes to a public repository that people have cloned from, the genie is out of the bottle. Good luck cleaning up your mess.
“Judge Tries to Unring Bell Hanging Around Neck of Horse Already Out of Barn Being Carried on Ship That Has Sailed.” - William G. Childs
For more details, see EditingHistory.
4.15. I committed a large binary file/files how do I delete them permanently?
If you want to remove file(s) that shouldn't have been added, use the ConvertExtension with --filemap option to "convert" your Mercurial repository to another Mercurial repository. You'll want to make sure that you set convert.hg.saverev=False if you want to keep in common the history prior to your removed file(s). If convert.hg.saverev=True, the conversion embeds the source revision IDs into the new revisions under an extra header, visible if via hg log --debug.
See also the previous question for other options.
4.16. I tried to check in an empty directory and it failed!
Mercurial doesn't track directories, it only tracks files. Which works for just about everything, except directories with no files in them. As empty directories aren't terribly useful and it makes the system much simpler, we don't intend to fix this any time soon. A couple workarounds:
add a file, like "this-dir-intentionally-left-blank". On *nix, you can do this with find . -type d -empty -exec touch {}/.keep \;. There is also the Mono-based tool MarkEmptyDirs which allows to automate this task).
- create the directory with your Makefiles or other build processes
4.17. I want to get an email when a commit happens!
Use the NotifyExtension
4.18. I'd like to put only some few files of a large directory tree (home dir for instance) under Mercurial's control, and it is taking forever to diff or commit
Just do a
printf "syntax: glob\n*\n" > .hgignore
or, if you are using 0.7 or below,
printf ".*\n" > .hgignore
This will make hg ignore all files except those explicitly added.
4.19. Why is the modification time of files not restored on checkout?
If you use automatic build tools like make or distutils, some built files might not be updated if you checkout an older revision of a file. Additionally a newer changeset might have an older commit timestamp due to pulling from someone else or importing patches somebody has done some time ago, so checking out a newer changeset would have to make the files older in this case.
If you need predictable timestamps you can use hg archive, which can do something like a checkout in a separate directory. Because this directory is newly created, there is nothing like switching to a different changeset afterwards, therefore the above mentioned problems don't apply here.
4.20. When I do 'hg push' to a remote repository, why does the working directory appear to be empty?
When changes are pushed to a repository, the working directory holding the repository is not changed. However, the changes are stored in the history and are available when performing operations on that repository. Thus, running commands like hg log in such a remote repository will show the full history even if a normal directory listing appears to be empty. (Repository publishing using hgweb also takes advantage of such history being available without needing a set of files in a working directory somewhere.)
Obviously, you can run hg update to make the files appear in such a repository, but unless you actually want to work within such a directory, it is arguably tidier to leave the directory in its "empty" state. This can be done by issuing an hg update null command in the directory holding the repository.
4.21. Any way to 'hg push' and have an automatic 'hg update' on the remote server?
[hooks] changegroup = hg update
This goes in .hg/hgrc on the remote repository.
4.22. How can I store my HTTP login once and for all ?
You can specify the usename and password in the URL like:
http://user:password@mydomain.org
Then add a new entry in the paths section of your hgrc file. With Mercurial 1.3 you can also add an auth section to your hgrc file:
[auth] example.prefix = https://hg.example.net/ example.username = foo example.password = bar
Please see the hgrc manpage for more information.
4.23. How can I do a "hg log" of a remote repository?
You can't. Mercurial accepts only local repositories for the -R option (see hg help -v log).
> hg log -R https://www.mercurial-scm.org/repo/hello abort: repository 'https://www.mercurial-scm.org/repo/hello' is not local
The correct way to do this is cloning the remote repository to your computer and then doing a hg log locally.
This is a very deliberate explicit design decision made by project leader Matt Mackall (mpm). See also issue1025 for the reasoning behind that.
4.24. How can I find out if there are new changesets in a remote repository?
To get the changeset id of the tipmost changeset of a remote repository you can do:
> hg id -i -r tip https://www.mercurial-scm.org/repo/hello 82e55d328c8c
When it changes, you have new changesets in the remote repository.
4.25. What can I do with a head I don't want anymore?
4.26. The clone command is returning the wrong version in my workspace!
Clone checks out the tip of the default (aka unnamed) branch (see NamedBranches). Ergo, you probably want to keep your main branch unnamed.
4.27. Any way to track ownership and permissions?
If you're using Mercurial for config file management, you might want to track file properties (ownership and permissions) too. Mercurial only tracks the executable bit of each file.
Here is an example of how to save the properties along with the files (works on Linux if you've the acl package installed):
# cd /etc && getfacl -R . >/tmp/acl.$$ && mv /tmp/acl.$$ .acl # hg commit
This is far from perfect, but you get the idea. For a more sophisticated solution, check out etckeeper.
4.28. I get a "no space left" or "disk quota exceeded" on push
I get a "no space left" or "disk quota exceeded" on push, but there is plenty of space or/and I have no quota limit on the device where the remote hg repository is.
The problem comes probably from the fact that mercurial uses /tmp (or one of the directory define by environment variables $TMPDIR, $TEMP or $TMP) to uncompress the bundle received on the wire. The decompression may then reach device limits.
You can of course set $TMPDIR to another location on remote in the default shell configuration file, but it will be potentially used by other processes than mercurial. Another solution is to set a hook in a global .hgrc on remote. See the description of how to set a hook for changing tmp directory on remote when pushing.
4.29. Why do I get "abort: could not import module mpatch!" when invoking hg?
If your current directory is that of the Mercurial source distribution, it is possible that hg is looking in the local mercurial package directory and fails to find the mpatch.so extension module. The solution (for most situations) is to move out of the source distribution directory and to try again. This is a common Python pitfall: Python will often be confused by packages or modules in the current directory and will import packages/modules from these local locations instead of looking in the appropriate places. If you are trying to use hg on a checkout of the Mercurial software itself, you might want to check any PYTHONPATH environment variable that you may have set and remove "empty" paths. For example, at a shell ($) prompt:
$ echo $PYTHONPATH /home/me/lib:/home/me/morelib:
Here, the trailing comma (:) indicates that there is an empty final path in the list. This empty path is likely to become mapped to the current directory, and Python will then prefer to look at the current directory instead of its own package directories (containing your installed version of Mercurial). If you reset PYTHONPATH trimming off any such empty paths, the problem should go away:
$ export PYTHONPATH=/home/me/lib:/home/me/morelib
4.30. Why do I get a traceback and ImportError when invoking hg?
See the response to the previous question for a possible explanation and some solutions.
4.31. Why do I get "abort: requirement 'fncache' not supported!" when invoking hg?
In version 1.1 of a new repository format was introduced to work around file name limitations on Windows. Repositories created with Mercurial 1.1 or later will automatically have enabled the fncache repository format. You need Mercurial 1.1 or later to read these repositories. Repositories created with pre 1.1 Mercurial or with fncache disabled can still be read. See the page about the fncache repository format for more information.
4.32. Why won't Mercurial let me merge when I have uncommitted changes?
If hg merge fails with the message abort: outstanding uncommitted changes, it means that the usual process of merging two branches cannot proceed.
Consider the normal merge case, when the working directory is clean -- that is, there are no uncommitted changes and hg diff produces no output. Mercurial combines the revision being merged (the "other branch") with the working directory's revision (the "local branch"). It leaves the result of this merge in your working directory for you to test. When you approve the merge result, you commit it. The key insight: all of those changes are the result of the merge, i.e. they come from the local head, or the other head, or the combination (merge) of them.
Now consider what happens if the working directory already contains modified files -- that is, hg diff produces output. In this case, Mercurial has three states to worry about: your uncommitted changes, the local head, and the other head. That would be incoherent, since Mercurial only allows merging two heads (changesets) at a time. You might think Mercurial should save your uncommitted changes somewhere so you can do the merge and then restore your original changes, but that introduces additional complexity. (What if your merge affects some of the same code as your uncommitted changes? That means another merge will be required in the working directory after you commit the merge you were trying to do in the first place!) So Mercurial does not try; it requires you to have a clean working directory when you try to merge two heads.
In short, Mercurial is trying to keep one operation separate from another (local changes versus the merge) and avoid putting the working directory into some kind of special state (suspending local changes until they can be combined with the current revision).
There are four ways around this limitation:
- discard your uncommitted changes (only appropriate if they are temporary throwaway changes, and you don't need them anymore)
- commit your changes (only appropriate if they are done, working, and ready to commit)
- create a new working directory
- set aside your changes
The first two should be self-explanatory.
Creating a new working directory is a bit more overhead, but is simple and usually fast (unless your repository is very large). For example:
orig=`pwd` hg clone -u . . ../temp-merge cd ../temp-merge hg merge [...test the merge...] hg commit -m"merge with ..." hg push # to your previous repository cd $pwd hg update # to the new merge changeset
Setting aside half-finished changes is an interesting problem with a variety of solutions, including but not limited to:
- diff + patch
Use the Shelve extension
MQ (Mercurial Queues) (not for beginners!)
4.33. How do I overwrite branch x with branch y?
hg update x hg commit --close-branch -m 'closing branch x, will be overwriten with branch y' hg update y hg branch -f x hg ci
The result is a closed head in branch x, and a new commit which has as parent branch y. Don't try to just overwrite files in branch x with files in branch y because it will screw up future merges. This seems the correct way to do it.
5. Bugs and Features
5.1. I found a bug, what do I do?
Report it to the Mercurial mailing list at mercurial@mercurial-scm.org or in the bug tracker.
5.2. What should I include in my bug report?
Enough information to reproduce or diagnose the bug. If you can, try using the 'hg -v' and 'hg --debug' switches to figure out exactly what Mercurial is doing.
If you can reproduce the bug in a simple repository, that is very helpful. The best is to create a simple shell script to automate this process, which can then be added to our test suite.
5.3. Can Mercurial do <x>?
If you'd like to request a feature, please send your request to mercurial@mercurial-scm.org.
Be sure to see ToDo and MissingFeatures to see what's already planned and where we need help.
6. Web Interface
6.1. How do I link to the latest revision of a file?
Find the URL for the file and then replace the changeset identifier with tip.
6.2. How do I change the style of the web interface to the visually more attractive gitweb?
In hgrc set
[web] style = gitweb
To switch back to the default style specify "style = default" (see hgbook).
7. Technical Details
7.1. What limits does Mercurial have?
Mercurial currently assumes that single files, indices, and manifests can fit in memory for efficiency.
There should otherwise be no limits on file name length, file size, file contents, number of files, or number of revisions (see also BigRepositories for the sizes of some example repositories.)
The network protocol is big-endian.
File names cannot contain the null character or newlines. Committer addresses cannot contain newlines.
Mercurial is primarily developed for UNIX systems, so some UNIXisms may be present in ports.
Mercurial encodes filenames (see CaseFolding, CaseFoldingPlan, fncacheRepoFormat) when storing them in the repository. Most notably, uppercase characters in filenames are encoded as two characters in the filename in the repository ("FILE" → "_f_i_l_e").
7.2. How does Mercurial store its data?
The fundamental storage type in Mercurial is a revlog. A revlog is the set of all revisions of a named object. Each revision is either stored compressed in its entirety or as a compressed binary delta against the previous version. The decision of when to store a full version is made based on how much data would be needed to reconstruct the file. This lets us ensure that we never need to read huge amounts of data to reconstruct a object, regardless of how many revisions of it we store.
In fact, we should always be able to do it with a single read, provided we know when and where to read. This is where the index comes in. Each revlog has an index containing a special hash (nodeid) of the text, hashes for its parents, and where and how much of the revlog data we need to read to reconstruct it. Thus, with one read of the index and one read of the data, we can reconstruct any version in time proportional to the object size.
Similarly, revlogs and their indices are append-only. This means that adding a new version is also O(1) seeks.
Revlogs are used to represent all revisions of files, manifests, and changesets. Compression for typical objects with lots of revisions can range from 100 to 1 for things like project makefiles to over 2000 to 1 for objects like the manifest.
7.3. How does Mercurial handle binary files?
Core Mercurial tracks but never modifies file content, and it is thus binary safe. See BinaryFiles for more discussion of commands which interpret file content, e.g. merge, diff, export and annotate.
7.4. What about Windows line endings vs. Unix line endings?
See Win32TextExtension for techniques which automatically convert Windows line endings into Unix line endings when committing files to the repository, and convert back again when updating the workspace. This is not default Mercurial behaviour, and requires users to edit their configuration files to turn it on. Adopting this policy on line endings probably implies enabling a hook to prevent non-compliant commits from getting into your repository, which in turn forces people contributing code to enable the extension.
7.5. What about keyword replacement (i.e. $Id$)?
See KeywordExtension.
7.6. How are Mercurial diffs and deltas calculated?
Mercurial diffs are calculated rather differently than those generated by the traditional diff algorithm (but with output that's completely compatible with patch of course). The algorithm is an optimized C implementation based on Python's difflib, which is intended to generate diffs that are easier for humans to read rather than be 'minimal'. This same algorithm is also used for the internal delta compression.
In the course of investigating delta compression algorithms, we discovered that this implementation was simpler and faster than the competition in our benchmarks and also generated smaller deltas than the theoretically 'minimal' diffs of the traditional diff algorithms. This is because the traditional algorithm assumes the same cost for insertions, deletions, and unchanged elements.
7.7. How are manifests and changesets stored?
A manifest is simply a list of all files in a given revision of a project along with the nodeids of the corresponding file revisions. So grabbing a given version of the project means simply looking up its manifest and reconstructing all the file revisions pointed to by it.
A changeset is a list of all files changed in a check-in along with a change description and some metadata like user and date. It also contains a nodeid to the relevant revision of the manifest.
7.8. How do Mercurial hashes get calculated?
Mercurial hashes both the contents of an object and the hash of its parents to create an identifier that uniquely identifies an object's contents and history. This greatly simplifies merging of histories because it avoid graph cycles that can occur when a object is reverted to an earlier state.
All file revisions have an associated hash value (the nodeid). These are listed in the manifest of a given project revision, and the manifest hash is listed in the changeset. The changeset hash (the changeset ID) is again a hash of the changeset contents and its parents, so it uniquely identifies the entire history of the project to that point.
7.9. What checks are there on repository integrity?
Every time a revlog object is retrieved, it is checked against its hash for integrity. It is also incidentally doublechecked by the Adler32 checksum used by the underlying zlib compression.
Running 'hg verify' decompresses and reconstitutes each revision of each object in the repository and cross-checks all of the index metadata with those contents.
But this alone is not enough to ensure that someone hasn't tampered with a repository. For that, you need cryptographic signing.
7.10. How does signing work with Mercurial?
Take a look at the hgeditor script for an example. The basic idea is to use GPG to sign the manifest ID inside that changelog entry. The manifest ID is a recursive hash of all of the files in the system and their complete history, and thus signing the manifest hash signs the entire project contents.
7.11. What about hash collisions? What about weaknesses in SHA1?
The SHA1 hashes are large enough that the odds of accidental hash collision are negligible for projects that could be handled by the human race. The known weaknesses in SHA1 are currently still not practical to attack, and Mercurial will switch to SHA256 hashing before that becomes a realistic concern.
Collisions with the "short hashes" are not a concern as they're always checked for ambiguity and are still long enough that they're not likely to happen for reasonably-sized projects (< 1M changes).
See also: https://www.mercurial-scm.org/pipermail/mercurial/2009-April/025526.html by Matt Mackall.
7.12. How does "hg commit" determine which files have changed?
If hg commit is called without file arguments, it commits all files that have "changed" (see commit). Note however, that Mercurial doesn't detect changes that change neither the file time nor its size (This is by design. See also issue618 and DirState).
7.13. What is the difference between rollback and strip?
They overlap a bit, but are really quite different:
rollback will remove the last transaction.
- Transactions are a concept often found in databases. In Mercurial we start a transaction when certain operations are run, such as commit, push, pull... When the operation finishes successfully, the transaction is marked as complete. If an error occurs, the transaction is "rolled back" and the repository is left in the same state as before.
You can manually trigger a rollback with hg rollback. This will undo the last transactional command. If a pull command brought 10 new changesets into the repository on different branches, then hg rollback will remove them all.
Please note: there is no backup when you rollback a transaction!
- Transactions are a concept often found in databases. In Mercurial we start a transaction when certain operations are run, such as commit, push, pull... When the operation finishes successfully, the transaction is marked as complete. If an error occurs, the transaction is "rolled back" and the repository is left in the same state as before.
strip will remove a changeset and all its descendants.
- The changesets are saved as a bundle, which you can apply again if you need them back.