Evolve User Interface Discussion
Note:
This page is primarily intended for developers of Mercurial.
|
There are a number of things that have to be discussed about how the Evolve UI works.
1. Low Hanging Fruits
Check the list easy bug and feature request related to evolution
Here is an handfull of highlight (but you should just check the bts list)
If you feel bold also look at all evolution related bug on the BTS
2. Glossary
Which language should we use for Evolve? Remember that once this goes into core, this language gets frozen forever.
2.1. Command names
![]() This sub-section need rework/splitting/movement/unicorn before being useful
This sub-section need rework/splitting/movement/unicorn before being useful
evolve: Automatically solve troubled commits. Get rid of stabilize and solve aliases?
previous and next: Move up and down the DAG. No more gup and gdown aliases?
- I'm in favor of removing gup and gdown. I never liked gup because it has "up" in its name and could be confused for "update." -- indygreg
touch: Create a new identical commit but identical to obsolete commit. Rename to restore and limit source to obsolete commits?
- +1 for restore. "touch" never made much sense to me. "touch" is also overloaded in UNIX speak to draw up associations with files. --indygreg
prune: Mark a commit as obsolete, optionally as replacing one. Remove kill and obsolete aliases.
fold: Fold various commits into one. Add a squash alias? Ok since git doesn't have a squash command.
reorder: Proposed command that permutes commits. With this proposed command, the Evolve UI completely replaces all uses of the histedit UI.
2.2. Concepts
![]() This section need rework/splitting/movement/unicorn before being useful
This section need rework/splitting/movement/unicorn before being useful
Successor/precursor: An obsolescence marker can indicate the commit that replaces the obsolete commit. The replacement is a successor, and the obsoleted commit is a precursor. These names are a bit ambiguous, because they sort of are synonyms for descendants and ancestors. Possible alternative language: replacement commit and original commit, with corresponding revset functions.
Unstable commits: Commits that hg evolve will have to fix. There are three kinds of unstable commits:
Orphan commits: non-obsolete commits based on obsolete commits.
If the obsolete commits have a replacement, hg evolve rebases unstable commits to the replacement. If there is no replacement, hg evolve rebases unstable commits to the root of their obsolete ancestors.
phase-divergent commits: replacement commits whose original commit got turned into the public phase by a pull. Better terminology: invalidated replacements?
- Since it is no longer valid to edit a now-public commit, the best that can be done for invalidated replacements is to create a diff between the replacement and the original and add that as a new commit.
content-divergent commits: Two conflicting replacement commits for the same original commit.
What should hg evolve do here?
2.3. Terminology Opinions
![]() This section need rework/splitting/movement/unicorn before being useful
This section need rework/splitting/movement/unicorn before being useful
Ideally we're searching for a grammar where everything is related. If we have words that are closely associated in the English language, users will associate them with related version control tasks. It reduces the potential for confusion and increases the probability for knowledge recall. With that in mind, I'm not sure words like "evolve" and "troubled" go together well. You wouldn't think "this thing is troubled, therefore I'm going to evolve it." I would think "stablize" or "solve" would be much better verbs to complement "troubled." "This thing is troubled, therefore I'm going to stablize it" makes more sense, IMO. But I think there's still room for improvement in the grammar. --indygreg
An idea is to name unstable changesets dangling changesets, to name bumped changesets dangling replacements, and to name divergent changesets conflicting replacements. Here, "dangling" means "doesn't have a suitable parent". In the case of normal changesets, this means that the parent is obsolete. In the case of replacement changesets, this means that the parent is public. -- tomjb
3. Commands
![]() This section wants to be:
This section wants to be:
- Summary of existing commands and alias
- One section per command//action
- Quick reminder of the command//action role and spirit
- Discuss for name change
- Discuss flag names
3.1. hg fold
3.1.1. Current state
The current behavior can be illustrated easily with the following examples:
hg fold .^: Makes a commit with the content of current working copy and it's parent.
hg fold --exact 3+4: Makes a commit with the content of revision 3 and 4 and insert it where 3 and 4 were
hg fold 3+4: Makes a commit with the content of revision 3, 4 and all of the revisions linearly between 3,4 and the working copy parent
3.1.2. Why?
In the dawn of time, the behavior was: hg fold <revset>:
fold everything in <revset> together.
There was two issue with this UI:
- It pretty much requires the knowledge of revset to be used efficiently. This put the barrier of entry higher than necessary for a fairly basic command.
The most common case turned out to be, I want to fold the last N commits. This happen commonly when one is working toward something, making frequent wip commit along the way to be able to easily go back to a check point. So the common case was hg fold X::.
So, we move the default to :
hg fold <rev> : folds everything between '.' and <rev>
hg fold --exact <revset>: folds everything in the revset
This also makes sense because most of mercurial command behave according the working directory parent
commit -> make a commit as child as '.'
amend -> add content to '.'
uncommit -> remove content to '.'
hg split -> split '.' into multiple changeset
diff -> show difference with '.'
revert -> restore file as in '.'
merge -> merge '.' with something else
rebase -> rebase '.' somewhere else (by default)
graft -> get a new commit on top of '.'
histedit -> histedit from '.' to X (would be nice to have an '--exact' here actually as well)
hg evolve -> evolve stuff related to '.'
3.1.3. Open Questions
- Are we satisfied with the name of the flag --exact? Is it descriptive enough?
- new flag?:
- When the user gives one changeset to the fold command, he/she wants to fold from that changeset to the parent of the working copy.
- When fold is given several changesets, the intent of the user is not as clear. Do we want to introduce a new flag to disambiguate the behavior here?
4. Behavior
4.1. Insertion / extraction
Automatic evolution is great at solving orphan situation and provides a powerfull step by step user experience. However it is not great are dealing with intended parentship changes like operation to "extract" a changeset from stack or "insert" a new changeset in a stack, or reordering them.
To some extend this kind of changes is the "territory" of PlanHistoryRewritePlan, but it make sense to think about them when thinking about history rewriting user interface.
To deal with this needs, I think the amend command could gain a --extract and a --insert flags. (This probably apply to most history rewritting command, but lets focus on amend)
* hg amend --extract would signal that a changeset should be "extracted" from
- the stack and create a new topological head, its former children being relocated on its parents.
* hg amend --insert would signal that a changeset should in insert inside the existing stack, its sibling being relocated above it.
The details of how it would be stored, exchanged and put to us are still to be decided.
Lets look at some example
4.1.0.1. extract
Lets imagine this graph, with B checked out:

hg amend --extract
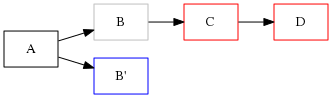
Automatic movement would not evolve the children of B on B', but it will move them to its parent: A.

4.1.0.2. insert
Lets imagine this graph, with A checked out

hg commit --insert -m B get us in the following situation

Automatic movement would rebase the sibling of B (children of A) on B

4.2. Automatic "hg evolve" call
![]() This sub section need rework/splitting/movement/unicorn before being useful
This sub section need rework/splitting/movement/unicorn before being useful
![]() no decision are will be made on this any time soon, concider using your brain power elsewhere.
no decision are will be made on this any time soon, concider using your brain power elsewhere.
Many evolve commands produce unstable changesets. Should they immediately call hg evolve by default?
4.2.1. pros
- Most (?) of the time, hg evolve will work without problems.
- Nicer for the user for the magic to happen automatically by default
4.2.2. cons
- Makes the user immediately handle instability
 This is a very serious downside. Currently, there is no way at all to cancel a merge conflict. Once you are in this state, you are stuck and have to do a serious biopsy. Agreed, we should absolutely not do this by default, nor have a config option. I'm ok with an hg commit --amend flag that does this for you automatically though. -- sid0
This is a very serious downside. Currently, there is no way at all to cancel a merge conflict. Once you are in this state, you are stuck and have to do a serious biopsy. Agreed, we should absolutely not do this by default, nor have a config option. I'm ok with an hg commit --amend flag that does this for you automatically though. -- sid0
- If you need to amend multiple changeset, you'd be stuck having to do multiple back-and-forth updates.
- This is also concerning. This is O(N^2) work rather than O(N) that incremental hg evolve runs allow. -- sid0
- Letting the user decide when to deal with rebases and merge conflicts might be nicer.
Perhaps ui.autoevolve option? On by default? Off by default?
I think auto evolve makes sense in some cases. For example, say you amend a commit with descendants and only change the commit message. Why wouldn't you want auto evolve in that scenario? -- indygreg
I'd be OK with having an autoevolve option (on first blush I'd rather have it be enabled by default, but I'd need to use evolve more to be sure. Maybe that would lead to having too many obsolete revisions). -- AngelEzquerra
What about an intermediate behavior? Couldn't it be possible to do a sort of "dry run evolve" which detected if there would be any conflicts during evolve, and if there weren't (e.g. in cases in which we just edited the changeset metadata). I think this would achieve 80% of the magic with 0% of the risk -- AngelEzquerra
I think the "there are now troubled commits message" should be actionable. Currently it just prints the count of troubled commits. I'd really like to see a "run hg evolve to stablize" message. If we don't auto evolve, at least we can tell the user what they should probably be doing next. -- indygreg
5. Use Cases
5.1. Undoing an amend
Users will often accidentally amend a commit. We need a good story to undo them.
This mean changing the commit content, but not touching the working directory. The hg uncommit command is already responsible for this action.
Growing a was to easily call uncommit on the precursor instead of the parent would fit that need:
hg uncommit -r 'precursor(., 1)'
hg uncommit --precursor
hg uncommit -P
(Git have a git reset HEAD@{1} notation for this. However, introducing a git-reset like command in Mercurial is a non-goal)
6. Pain Points
6.1. Evolve can "stabilise" to unstable destination
6.1.1. Situation
Start with a linear graph:

and amend 1 and 3 to create aa' and bb'. This gives us this graph:
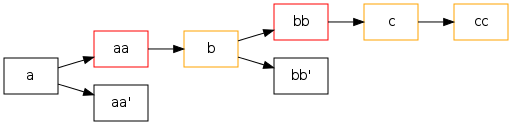
The red changesets are marked as obsolete, and the orange changesets are thus troubled. Starting from bb, getting this repo back into an untroubled state takes 6 calls to 'hg evolve', the last 4 of which need --any.
6.1.2. Explanation of the current behavior
This happens because evolve first started to rebase c and cc on B. After that it asked to --any to start evolving B, BB' and C' and CC' over aa'.
6.1.3. Possible improvement
The shortest path to stabilization would have been to take care of B and BB' first then directly evolve C and C on the result.
The fact that hg evolve think evolve B is unrelated to BB' (then requires --any) sounds wrong too.
Both point can be fixed if we make evolving ancestors "relevant to the context" (not requires any).
(This case is not a valid case in favor of hg evolve --all)
6.2. The obsolete history is not very usable
![]() This section need some clarification
This section need some clarification ![]() consider using a 1. Example 2. explanation 3. possible actions format
consider using a 1. Example 2. explanation 3. possible actions format
In order for evolve to achieve its full potential the hidden history that that evolve creates must be not only useful for enabling amending shared revisions but also _usable_ by the user to get back to old versions of a given revision (e.g. in case that the user is not happy with a later version of that revision).
Currently the obsolete history created by evolve is not very usable because the number of hidden, obsolete revisions created by evolve is greater than it should. In particular:
- Each history modification step creates its own set of obsolete revisions. There is no way to perform several history editing operations and combining those into a single operation.
![]() Why do you say evolve creates more obsolete changeset that it could. Do you have a concrete example of situation where it does? (beside the extra temporary commit thing)
Why do you say evolve creates more obsolete changeset that it could. Do you have a concrete example of situation where it does? (beside the extra temporary commit thing)
-- AngelEzquerra When I use MQ I often import a bunch of revisions into MQ, I unapply some (maybe a lot) of them, I reorder them, reapply them, fold some, split some, amend some... With evolve, each and every one of those actions will potentially create as many obsolete revisions as the number of revisions I would have imported into MQ. With some planning, perhaps using the reorder command or thinking ahead I could minimize the number or revisions, but still, for any non trivial history editing operation (and perhaps even for some trivial operations) the number of obsolete revisions may explode. Even worse, when using a GUI it may be even harder to "plan" to reduce the number of obsolete revisions as each GUI operation must be mapped to evolve commands.
Another thing that comes to mind and that I think contributes to this feeling that evolve creates too many revisions is that obsolete revisions don't have record of the evolve operation that created them. What I mean by that is that you may do 3 history editing operations and get a lot more obsolete revisions. But I don't really care about those revisions individually. Instead I care about the 4 states of the repo related to those 3 history editing operations (original state, state after operation 1, state after operation 2, state after operation 3). Which leads me to the filtering idea below.
An alternative to this would be for evolve to provide tools to filter or show the obsolete history somehow.
![]() This second point is very interesting, there is multiple direction where we could improve that. Can you elaborate on your filtering idea?
This second point is very interesting, there is multiple direction where we could improve that. Can you elaborate on your filtering idea?
-- AngelEzquerra: What I'm thinking is that there should be a way to to show repository "states", instead of showing all the obsolete revisions.
I think that once I'm done editing my story I a generally only care about the original state (right before I editing history) and the state afterwards (the one that is visible, i.e. not obsolete). _While_ I am editing history I will probably also care with the state right before the last evolve operation, and much less often about the other intermediate states (as in states after an evolve operation). Usually I would only care about intermediate states if I made a mistake or I wanted to go back to a previous state).
We we could do a couple of things: 1. Track the actions that created sets of obsolete operations (i.e. repo states) 2. We could perhaps track when we start editing history (e.g. when we do our first history editing operation after a non history editing operation) and when we finish (e.g. when we do the first non history editing operation after a non history editing operation after a group of editing operations). In doing so we could automatically tell which was the "original state" and make it accessible through some revset, or have some log option that would only show those _evolve start_ states. If we also tracked the evolve operations that created the obsolete revisions we could filter the log by the different states the repo went through during the history editing operations, effectively letting you turn back the clock to any previous state in your repo.
I don't know if this makes sense to you guys...
7. F.A.Q.
7.1. Why do we have a temporary commit after amend?
It is an implementation details that will eventually be removed
7.2. Why are hidden changesets not pushed to remote?
Pushing all hidden changeset to the remote by default does not seems to be an interesting goal. However having some way to push or pull some obsolete/hidden changeset in some case seems useful and will probably happen. (This is however not very high priority right now).